
It’s a cold, hard world for a search engine. People ask you for guidance; you scan millions of pages for them, give them the best results you can find, and they never say thanks. You’re treated as a functionary, ignored until they need you again. (Sniff.)
Still, it’s an engine-eat-engine world. You’ve got a job to do, and you’re going to do it the very best you can. It means a lot when people turn to you over the others, and to keep their trust, you have to keep getting better all the time, outrun the other search engines, and deliver the tastiest results.
Some content marketers are good at optimization, helping you out with alt-text on photos, meaningful content, and metadata that make it utterly clear what the page is about. When you can deliver exactly what a searcher’s asked for, it’s a kind of elegance, like a dancer’s perfected executed pirouette or catching the best-ever wave at precisely the right time. An almost physical pleasure. If you had a body, you’d walk a little taller.
You’re a master at detecting the nuances between pages. Like a bloodhound, you sniff for the tendrils of meaning that help you sort an A page from an A+ page. And through training and time, you’ve developed the ability to often tell when someone is trying to manipulate you. When you discover someone gaming your system, you do have a trump card to play: You can choose not to display that site in search results, so that it can’t fool or disappoint an eager searcher again.
There is one snag content marketers could unravel for you and themselves, one issue often created by honest people wishing to share good content that ironically causes you an unnecessary problem: Duplicate content. Okay, we’ll tell the world about this for you.
Why duplicate content is a problem
(Caveat: What follows is a high level simplification of duplicate content, intended as very basic information for the marketer who creates content. If you’re an active SEO practitioner, there are many duplicate content issues (such as URL parameters and session IDs, etc.) that this article does not address at all. For the more advanced, we suggest Moz’ Best Practices guide, “What is Duplicate Content?”
“Duplicate content” is an issue created when one website hosts two pages of content that are the same or nearly so, or two (or more) websites host a page of virtually identical content. Here’s an illustration of the kind of problems it causes:
Site A published a lovely 600-word biography of Charles Dickens’ third wife. Site B wanted to share the biography with its readers, and asked for permission to publish it on the Site B blog. Permission granted. Site B posted the article on its own site. The copy was the same, but the blog post had a slightly different title, and its URL was different.
- The URL of Site A’s page is this: www.sitea.com/Dickens-third-wife-ran-coffee-shop.
- The URL of Site B’s page is this: www.siteb.com/ Dickens-beloved-third-wife-Althea-ran-coffee-shop.
You, dear reader, ask your phone: “Who was Charles Dickens’ third wife, and what happened to her?”
If the search engine determines that the 600-word biography is the best answer to your request, the engine doesn’t know whether to pick the page on Site A or Site B to return. It sniffs for any differences (perhaps site authority will help it decide), but essentially, it’s in a quandary. Not a good place for a busy search engine to get hung up, and the engine will get miffed about this.
Google and the other engines dislike duplicate content because it makes their jobs harder and interferes with their ability to return the best results. (Returning good results is how search engines wax and wane in our affection, ergo how they can charge for advertising – how they live and die.) And when they find duplicate content on your pages, they have the power to vent this displeasure by ignoring you, thus making your website harder to find – putting a major crimp in your inbound marketing efforts.
Making it straightforward and easy for a search engine to find and evaluate your content is called “search engine optimization.” There’s no common term for the opposite of SEO, but perhaps there should be. (Suggestions welcome.)
Duplicate content on your own site(s)
The fix for this is easy. There is never a good reason for duplicate content on your own site. Each page should have its own unique story to tell, and no two pages should tell the same exact story. Suppose you breed and sell Yorkshire terriers, and your goal is to get people to choose a Yorkie over another breed. You need only one page that focuses on the breed’s lovable disposition. That disposition can be mentioned on other pages, but each page should have its own focus (how to train, what to feed, lifespan, history, how to buy, etc.). Those other pages can mention temperament and link to the page on disposition; that’s a good thing for the reader, and so it’s good for SEO too.
If you have multiple sites and have content that would be good on all sites, you can post it on them all; read on, and pay special attention to the “rel=canonical” information at the end.
Duplication by content farms
It’s still common for “content farms” to grab a good story off the web and spin it, mechanically or otherwise. The goal is to tell the same story (and get the same valuation of content) while changing just enough so the search engines don’t recognize it as duplicate content. It’s a form of plagiarism, a black-hat technique, and the search engines will pounce if they discover it. (Bravo!) If you’re hiring an agency of some kind to help you create content, make sure they aren’t spinning the content of others. If spun duplicate copy is found on your site, you are the one who will pay the penalty, no matter how innocently you purchased it or who you hired to create it for you. (Aside: Good content costs time, or money, or both; there are no real shortcuts. Buyer beware.)
Curation should not be duplication
Sometimes you find a story that’s so smart or useful or well-written that you want to share it. You can always call attention to it in a tweet or Facebook posting (attributing it to its author, of course). If you simply re-post it, this innocent share can begin as a form of appreciation … but end in duplicate content. If you want to curate someone’s content, that’s a welcome form of sharing as long as you do it correctly. The (unwritten) rules are:
- Share only what you know your own readers will appreciate finding.
- Don’t republish the entire story. Pick snippets or a few paragraphs.
- Give credit to the original author or site, and link to the original content.
- Include your own opinion. Have something unique to say; this is what will really signify that your piece is an original work. Your own words should form the bulk of the article.
- It’s nice, and good manners (if not always strictly practical or necessary) to touch base with the author first and let them know you’re curating their piece. People with half a million followers or columns in major newspapers may not respond, but people who are well known in their fields (if not exactly public personages) may, and they’ll often appreciate it.
Think of it like a book review: You’re adding value by drawing attention to the book, and you’re adding value with your commentary. You’re not reprinting the book (but you do link to it so that people can easily find and read it).
What is a rel=canonical? – and why you should care
Sooner or later there will be an article or blog post that you want to essentially reprint in toto. Maybe someone just said something so perfectly that you don’t want to cut it and curate it – you want to republish the whole thing, just as it is, for the benefit of your readers. Or maybe you wrote a guest post for another website or blog, and you want your own readers to see it. You can do this without risking the duplicate-content wrath of Google (et alia) by using a rel=canonical tag in the metadata of the republished article.
You can think of a rel=canonical as a URL direction to a “canonical” page. A “canon” is a bedrock principle, an accepted standard, the essential base of something, etc. A “canonical” page is the essential, original, source page; “rel=” means “relationship.” So, rel=canonical essentially means “the canonical version of this page is to be found at this URL address.” (More detailed, in-the-weeds information about canonical links can be found here.)
Most web pages have a rel=canonical in their metadata fields already. The default is usually the URL of the web page. If you use a content management system, it’s likely that the rel=canonical is a standard tag, and by default uses the page’s own URL.
Recently Ricky Bandelin of Industrial Quality Management wrote a good guest post on deliverability that we published in Act-On’s Marketing Action blog. Here’s what the rel=canonical in the source code looks like on our site:

Ricky posted the article on his own site as well. Note that while most of his source code is different, the rel=canonical is the same as on Act-On’s blog. It is telling Google (or any search engine) that the original content is over there, at that Act-On URL. It behaves as a kind of redirect for Google (et.al.).

Now suppose someone searches for duck + deliverability + email. Google can look at both pages and know which one to return. The web page displaying the Act-On blog will be the one shown to the searcher because in both locations where this content lives, everyone agrees that the Act-On blog page is the canonical page.
To go back to our example of Mrs. Dickens’ 600-word biography:
The URL of Site A’s page is www.sitea.com/Dickens-third-wife-ran-coffee-shop. The rel=canonical is:
- <link rel=”canonical” href=”https://sitea.com/Dickens-third-wife-ran-coffee-shop/” />
The URL of Site B’s page is www.siteb.com/Dickens-beloved-third-wife-Althea-ran-coffee-shop. But the rel=canonical is the same now as Site A’s:
- <link rel=”canonical” href=”https://sitea.com/Dickens-third-wife-ran-coffee-shop/” />
The search engines know exactly which page to return; there are no issues for them. And Site B’s content marketer gets to show their readers great content with no duplicate content risk. .
Set up a rel=canonical link in a content management system
You don’t have to be a code wizard to set this up. We’ll use a blog post as our example.
If you use WordPress and Yoast:
1. Prep your draft blog post in WordPress
2. Go to the web page of the post or article you wish to republish; copy the URL
3. Go back to your draft in your WordPress app
4. Click “Advanced” in the SEO panel
 5. In the panel that opens, scroll down to the canonical URL field.
5. In the panel that opens, scroll down to the canonical URL field.
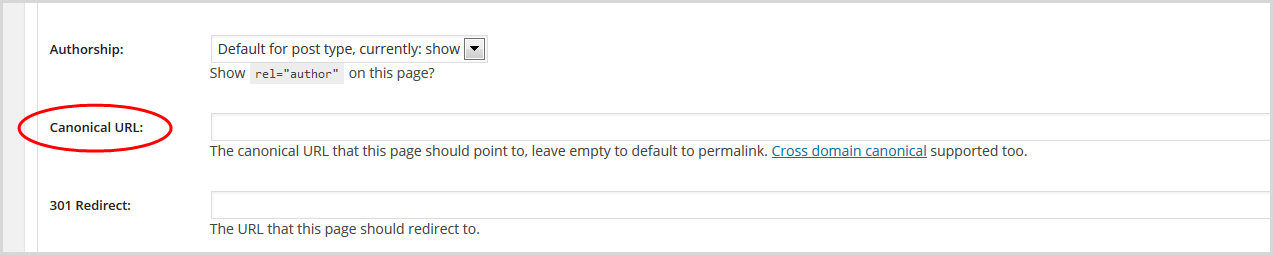
6. Enter the URL you copied. The Yoast plug-in will add the rel= bit for you
For other content management systems, there is often a similar rel=canonical field or its equivalent.
If there is no obvious field, you can create a rel=canonical link in your page’s source code.
Set up a rel=canonical directly in the source code
 1. Set up your blog post as a draft
1. Set up your blog post as a draft
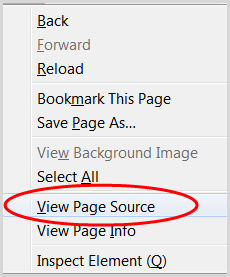
2. Go to the page with the content you want to republish
3. Right-click and choose “View Page Source”
4. On the page, look for the rel=canonical meta tag
5. Copy the entire tag sequence
It should look much like this:
<link rel=”canonical” href=”https://www.what-ever-the-text-actually-is/“ />
6. Replace your own rel=canonical tag with the one you copied
Now, when you push this post live, your metadata will let Google know where the canonical version of this page lives. Congratulations; you’ve just made a search engine very happy. And that’s a good thing.
For more information about rel=canonical, see Google’s post “5 Common Mistakes with Rel=Canonical.”
For more information on basic SEO, read SEO 101: The Basics and Beyond
NB: The photograph is actually of Catherine Hogarth Dickens, Charles Dickens’ one and only wife.